| 處理方式 | 代碼名稱 |
| 1. 使用Python的xlwings類庫,讀取Excel文件,然后采用Excel的Sheet和Range的引用方式讀取并計算 | XLS_READ_SHEET.py |
| 2. 直接使用Excel自帶的VBA語言進行計算 | VBA |
|
3. 使用Python的xlwings類庫,讀取Excel文件,然后采用Python的自帶數據類型List列表進行數據存儲和計算 |
XLS_READ_LIST.py |
使用Python的xlwings類庫,讀取Excel文件,然后引用Excel的Sheet和Range的方式來讀取并計算
#coding=utf-8
import xlwings as xw
import pandas as pd
import time
start_row = 2 # 處理Excel文件開始行
end_row = 10002 # 處理Excel結束行
#記錄打開表單開始時間
start_open_time = time.time()
#指定不顯示地打開Excel,讀取Excel文件
app = xw.App(visible=False, add_book=False)
wb = app.books.open('D:/PYTHON/TEST_CODE/Book300s.xlsx') # 打開Excel文件
sheet = wb.sheets[0] # 選擇第0個表單
#記錄打開Excel表單結束時間
end_open_time = time.time()
#記錄開始循環(huán)計算時間
start_run = time.time()
row_content = []
#讀取Excel表單前10000行的數據,Python的in range是左閉右開的,到10002結束,但區(qū)間只包含2到10001這一萬條
for row in range(start_row, end_row):
row_str = str(row)
#循環(huán)中引用Excel的sheet和range的對象,讀取B列和C列的每一行的值,對比計算
start_value = sheet.range('B' + row_str).value
end_value = sheet.range('C' + row_str).value
if start_value = end_value:
values = end_value - start_value
#同時測試List數組添加記錄
row_content.append(values)
#計算和
total_values = sum(row_content)
#記錄結束循環(huán)計算時間
end_run = time.time()
sheet.range('E2').value = str(total_values)
sheet.range('E3').value = '使用Sheet計算時間(秒):' + str(end_run - start_run)
#保存并關閉Excel文件
wb.save()
wb.close()
print ('結果總和:', total_values)
print ('打開并讀取Excel表單時間(秒):', end_open_time - start_open_time)
print ('計算時間(秒):', end_run - start_run)
print ('處理數據條數:' , len(row_content))
用Python直接訪問Sheet和Range取值的計算結果如下:
讀取Excel文件用時 4.47秒
處理Excel 10000 行數據花費了117秒的時間。

Option Explicit
Sub VBA_CAL_Click()
Dim i_count As Long
Dim offset_value, total_offset_value As Double
Dim st, et As Date
st = Time()
i_count = Sheets("Sheet1").Cells(Rows.Count, 1).End(xlUp).Row
i_count = 10001
For i_count = 2 To i_count
If Range("C" i_count).Value > Range("B" i_count).Value Then
offset_value = Range("C" i_count).Value - Range("B" i_count).Value
total_offset_value = total_offset_value + offset_value
End If
Next i_count
et = Time()
Range("E2").Value = total_offset_value
Range("E3").Value = et - st
MsgBox "Result: " total_offset_value Chr(10) "Running time: " et - st
End Sub
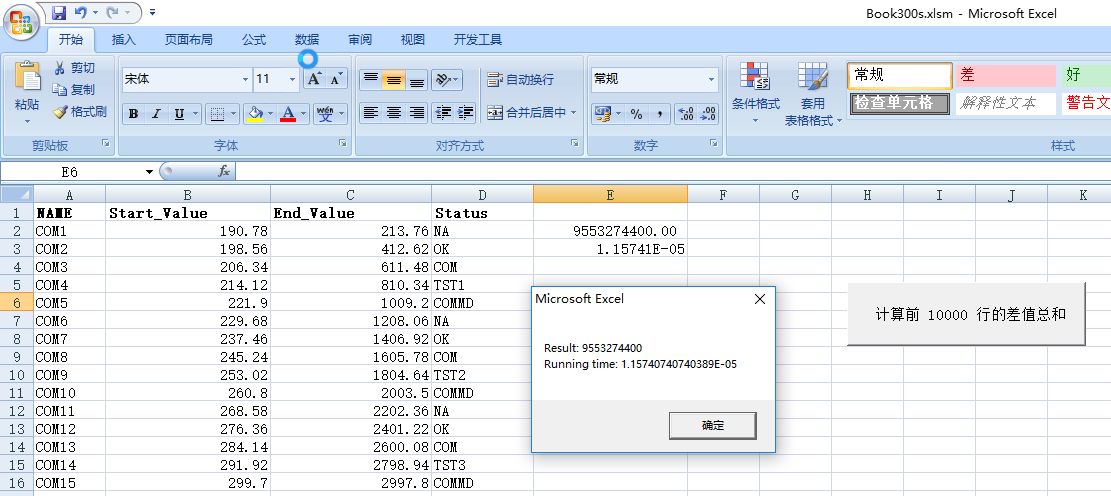
VBA處理計算結果如下:
保存了3萬條數據的Excel文件是通過手工打開的,在電腦上大概花費了8.2秒的時間
處理Excel 前10000行數據花費了1.16秒的時間。
#coding=utf-8
import xlwings as xw
import pandas as pd
import time
#記錄打開表單開始時間
start_open_time = time.time()
#指定不顯示地打開Excel,讀取Excel文件
app = xw.App(visible=False, add_book=False)
wb = app.books.open('D:/PYTHON/TEST_CODE/Book300s.xlsx') # 打開Excel文件
sheet = wb.sheets[0] # 選擇第0個表單
#記錄打開Excel表單結束時間
end_open_time = time.time()
#記錄開始循環(huán)計算時間
start_run = time.time()
row_content = []
#讀取Excel表單前10000行的數據,并計算B列和C列的差值之和
list_value = sheet.range('A2:D10001').value
for i in range(len(list_value)):
#使用Python的類庫直接訪問Excel的表單是很緩慢的,不要在Python的循環(huán)中引用sheet等Excel表單的單元格,
#而是要用List一次性讀取Excel里的數據,在List內存中計算好了,然后返回結果
start_value = list_value[i][1]
end_value = list_value[i][2]
if start_value = end_value:
values = end_value- start_value
#同時測試List數組添加記錄
row_content.append(values)
#計算和
total_values = sum(row_content)
#記錄結束循環(huán)計算時間
end_run = time.time()
sheet.range('E2').value = str(total_values)
sheet.range('E3').value = '使用List 計算時間(秒):' + str(end_run - start_run)
#保存并關閉Excel文件
wb.save()
wb.close()
print ('結果總和:', total_values)
print ('打開并讀取Excel表單時間(秒):', end_open_time - start_open_time)
print ('計算時間(秒):', end_run - start_run)
print ('處理數據條數:' , len(row_content))
用Python的LIST在內存中計算結果如下:
讀取Excel文件用時 4.02秒
處理Excel 10000 行數據花費了 0.10 秒的時間。

Python操作Excel的類庫有以往有 xlrd、xlwt、openpyxl、pyxll等,這些類庫有的只支持讀取,有的只支持寫入,并且有的不支持Excel的xlsx格式等。
所以我們采用了最新的開源免費的xlwings類庫,xlwings能夠很方便的讀寫Excel文件中的數據,并支持Excel的單元格格式修改,也可以與pandas等類庫集成使用。
VBA是微軟Excel的原生二次開發(fā)語言,是辦公和數據統(tǒng)計的利器,在金融,統(tǒng)計,管理,計算中應用非常廣泛,但是VBA計算能力較差,支持的數據結構少,編輯器粗糙。
雖然VBA有很多不足,但是VBA的宿主Office Excel卻是天才程序員基于C++開發(fā)的作品,穩(wěn)定,高效,易用 。
有微軟加持,VBA雖然數據結構少,運行速度慢,但訪問自己Excel的Sheet,Range,Cell等對象卻速度飛快,這就是一體化產品的優(yōu)勢。
VBA讀取Excel的Range,Cell等操作是通過底層的API直接讀取數據的,而不是通過微軟統(tǒng)一的外部開發(fā)接口。所以Python的各種開源和商用的Excel處理類庫如果和VBA來比較讀寫Excel格子里面的數據,都是處于劣勢的(至少是不占優(yōu)勢的),例子2的VBA 花費了1.16秒就能處理完一萬條數據。
Python基于開源,語法優(yōu)美而健壯,支持面向對象開發(fā),最重要的是,Python有豐富而功能強大的類庫,支持多種工作場景的開發(fā)。
我們應該認識到,Excel對于Python而言,只是數據源文件的一種,當處理大量數據時,Python處理Excel就要把Excel當數據源來處理,一次性地讀取數據到Python的數據結構中,而不是大量調用Excel里的對象,不要說頻繁地寫入Excel,就是頻繁地讀取Excel里面的某些單元格也是效率較低的。例子1的Python頻繁讀取Sheet,Range數據,結果花費了117秒才處理完一萬條數據。
Python的計算效率和數據結構的操作方便性可比VBA強上太多,和VBA聯(lián)合起來使用,各取所長是個好主意。
當Excel數據一次性讀入Python的內存List數據結構中,然后基于自身的List數據結構在內存中計算,例子3的Python只用了 0.1秒就完成了一萬條數據的計算并將結果寫回Excel。
| 處理方式-計算Excel里的一萬條記錄的差值的總和 | 效率 |
| 1. 使用Python的xlwings類庫,采用Excel的Sheet和Range的引用方式,按行讀取Excel文件的記錄并計算 | 差,計算用時 117秒 |
| 2. 直接使用Excel自帶的VBA語言進行計算,也是采用Excel的Sheet和Range的引用方式,按行讀取Excel文件的記錄并計算 | 很高 ,計算用時 1.16秒 |
|
3. 使用Python的xlwings類庫,一次性讀取Excel文件中的數據到Python的List數據結構中,然后在Python的List列表中進行數據存儲和計算 |
最高,計算用時 0.1秒 |
到此這篇關于淺談Python xlwings 讀取Excel文件的正確姿勢的文章就介紹到這了,更多相關Python xlwings 讀取Excel內容請搜索腳本之家以前的文章或繼續(xù)瀏覽下面的相關文章希望大家以后多多支持腳本之家!
標簽:隨州 興安盟 濟源 昭通 信陽 淘寶好評回訪 阜新 合肥
巨人網絡通訊聲明:本文標題《淺談Python xlwings 讀取Excel文件的正確姿勢》,本文關鍵詞 淺談,Python,xlwings,讀取,Excel,;如發(fā)現本文內容存在版權問題,煩請?zhí)峁┫嚓P信息告之我們,我們將及時溝通與處理。本站內容系統(tǒng)采集于網絡,涉及言論、版權與本站無關。